Data Scars & Data Shocks: The Long-Term Effects of Data Quality Issues
February 27, 2024

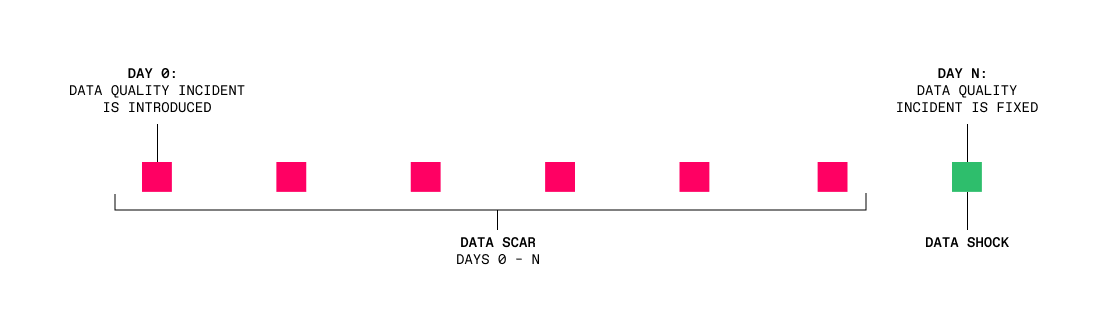
What happens when there is a data quality issue inside a table? Let’s say the issue starts occurring on Day 0, due to a broken data pipeline or a corrupted feed from a third party. On Day N, the issue is resolved, and data starts flowing into the table correctly once again. Problem solved — right?
Well, not exactly. What about those records in the table between Days 0 and N — where N could be 10, 20, or even 100+ days in the future? Those corrupted records have formed a scar in the data that data science, data engineering, and data analytics teams will have to work around for the foreseeable future. But that’s not all. When the issue is fixed on Day N, the fix represents a shock to machine learning models and data analytics.
 Let’s take a look at how data scars and shocks can impact your organization for months or even years after the original incident is resolved.
Let’s take a look at how data scars and shocks can impact your organization for months or even years after the original incident is resolved.
How data scars affect your systems
Data scars, a term we first heard used by Daniele Perito, Chief Data Officer & Co-Founder at Faire, are a chunk of missing, corrupted, incomplete, or otherwise poor-quality records in a table, caused by a data quality problem. This data cannot be trusted by systems operating on those records in the future.
Scars can only heal if the data is painstakingly and perfectly repaired, which is often very expensive and difficult to do. So, usually, scars from a data quality problem remain in our data even after the incident is resolved.
The systems affected by data scars include:
- Data pipelines: When a subset of records is different from the rest, data pipelines may require more complexity to handle exceptions and avoid biases, making them more difficult to write and maintain.
- Data analytics & data science: Anomalous data from the time of the scar will show up in reporting and/or visualizations, making it much more challenging to work with the data. You might think that the solution is to remove corrupted data from the dataset entirely. But this leads to its own set of problems. You end up with “data amnesia” — you can’t make time-based comparisons and it’s harder to analyze trends.
- Machine learning models: Models make future predictions based on historical data. If some of that historical data is low-quality, they will have worse performance even if they’re built long after the scar occurred. Data quality issues usually affect certain columns disproportionally, so you end up with models that don’t accurately interpret particular aspects (features) of the data.
As you can see from these examples, the longer and deeper the scar, the more lasting negative impact there will be.
How data shocks affect ML models
In machine learning and AI, it’s often common to talk about a sudden change in data “shocking” a model. The model has learned something from historical records, and suddenly, those patterns shift. The shift in consumer behavior caused by the COVID-19 pandemic is one of the most well-known examples of a data shock, rattling models for everything from supply-chain projections to personalized recommendations.
As we’ve just discussed above, a data scar can “shock” a model and cause it to perform poorly. But there’s a more insidious type of data shock that people don’t always consider, and this is the data shock that happens when the issue is fixed. This can be just as bad as the shock from the initial data quality issue itself!
How does this play out? Often, by the time a data quality issue is fixed, the model has already gone through several rounds of retraining on the new, scarred data. So it’s learned to account for those data scars in its predictions and to expect data to show up that’s corrupted or poor-quality.
Then, when the data quality issue is fixed, unless the model is immediately retrained (which rarely happens), it will continue behaving as if there’s an issue in the data. This causes its predictions on the new data to be inaccurate. The way to resolve this is to retrain the model, but often it’s necessary to wait until enough new high-quality training data has come in, prolonging the effects of the shock.
Data shocks can break analytics, too
When an incident is fixed, the data shock doesn’t just affect models. Unless the analytics and data science teams are tracking the incident resolution, they might see a sudden change in metrics and mistake it for a real event.
For example, imagine that for several months, data about Android usage was being double counted for some regions due to a data pipeline bug. When the issue is fixed, the product team sees a sudden drop in usage and starts a fire drill to figure out why customers are churning. Not only is this a waste of time, it can lead to bad decisions.
Automated data quality monitoring with AI reduces the impact of scars and shocks
Maintaining high-quality data at enterprise scale, across potentially tens of thousands of tables, is very hard. Many teams end up with a reactive approach. They fix issues once they start affecting metrics that bubble up to the CEO, or when someone on the team discovers a problem in the course of their data science or engineering work.
But it’s not just about the number of issues you fix or how significant each issue is. As we’ve learned, you have to find and fix data quality issues as quickly as possible to minimize the long-term effects. The longer a data quality issue goes unfixed, the deeper the scar, and the greater the shock from fixing it.
The good news is that with new AI technology, there are better solutions than ever for monitoring your data at scale. Anomalo uses AI algorithms to find anomalous data in tables with very little setup, and alert your team immediately. We even provide automated root-cause analysis for the fastest resolution.
To learn more about how Anomalo can help you and your business limit the impact of data scars and data shocks, request a demo.
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Ready to Trust Your Data? Let’s Get Started
Meet with our team to see how Anomalo transforms data quality from a challenge into a competitive edge.